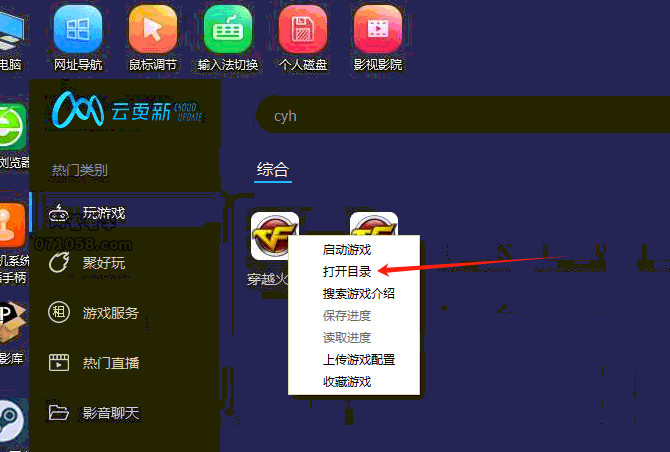
搜索到
162
篇与
的结果
-

-
-
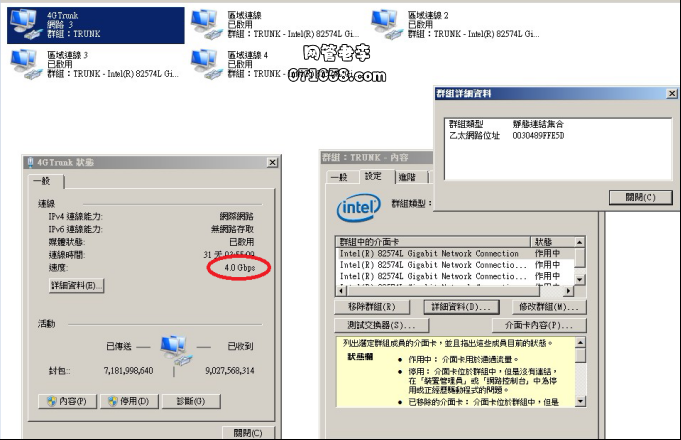
支持静态连结集合的网卡收集 多的废话不多说直接上列表理论上只要是Intel网卡应该都支持列表:Intel(R) Gigabit PT Quad Port Server Express ModuleIntel(R) PRO/100 S Server AdapterIntel(R) PRO/100 VE Desktop AdapterIntel(R) PRO/100+ Dual Port Server AdapterIntel(R) PRO/100+ Management AdapterIntel(R) PRO/1000 CT Network ConnectionIntel(R) PRO/1000 F Server AdapterIntel(R) PRO/1000 Gigabit Server AdapterIntel(R) PRO/1000 MB Dual Port Server ConnectionIntel(R) PRO/1000 T Desktop AdapterIntel(R) PRO/1000 T Network ConnectionIntel(R) PRO/1000 T Server AdapterIntel(R) PRO/1000 XF Network ConnectionIntel(R) PRO/1000 XF Server AdapterIntel(R) PRO/1000 XT Desktop AdapterIntel(R) PRO/1000 XT Network ConnectionIntel(R) PRO/1000 XT Server AdapterIntel(R) PRO/1000P Dual Port Server AdapterIntel(R) 82577LC Gigabit Network ConnectionIntel(R) 82566MM Gigabit Network ConnectionIntel(R) 82566MC Gigabit Network ConnectionIntel(R) 82567LF Gigabit Network ConnectionIntel(R) 82567V Gigabit Network ConnectionIntel(R) PRO/10GbE CX4 Server AdapterIntel(R) PRO/10GbE LR Server AdapterIntel(R) PRO/10GbE SR Server Adapter
-
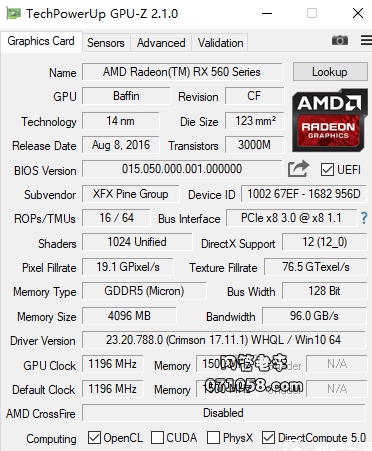
GPU-Z查看显卡体质方法 显卡是电脑中重要的核心组件之一,显卡体质可以说是鉴定显卡是否能超频的一项重要评分,一般来说70以上已经不错了,但是也不见得很准确,有的显卡68的体质照样超频能力很强,那么新版gpuz怎么看显卡体质呢?下面就来教给大家gpu-z查看显卡体质步骤。新版gpu-z查看显卡体质方法:1、首先打开GPU-Z软件,然后可以查看到各种显卡的信息和参数。2、如果想要在GPU-Z之中查看显卡的体质,那么点击到高级选项卡,在下拉框选择ASIC Quality。3、然后,我们在空白处单击右键,在弹出的如下界面点击进入倒数第二栏的设置。4、这样,我们就可以查看到显卡的体质了,使用百分数来表示,数值越高,体质越好。
-
宝塔面板装zfile教程 宝塔面板必须安装 Java 环境(Java 1.8)下载项目下载文件到服务器:https://c.jun6.net/ZFILE/zfile-release.jar宝塔网站配置如果填写了域名,访问域名即可(记得将域名指向服务),如果使用的是端口,则使用端口访问.或者你可以用反向代理的方式做域名绑定更新版本1.宝塔中停止 ZFile 程序(务必先停止,且尝试访问网页无法访问再继续下面的操作)2.重复步骤 下载项目 下载最新版本程序,覆盖原来的 zfile-release.jar 文件(其实就是先删除之前的,再将新版本程序放到同路径同名)3.启动项目,访问验证。(一般启动需要 1-3 分钟,访问如果还是之前的版本,请清除浏览器缓存!)其他设置宝塔 nginx 默认只支持上传最大 50MB 的文件,可去以下页面进行设置:
-
-
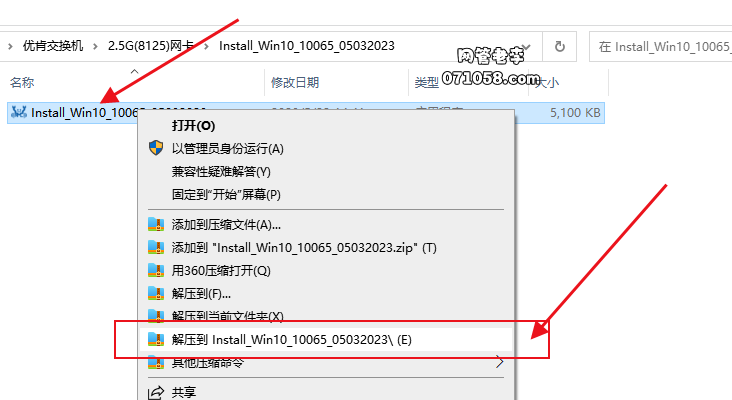
Realtek 8125 2.5G网卡测速慢的解决方法 在无盘服务器 客户机网卡PNP设置中把网卡驱动版本更新到最新版本驱动自动更新:直接选择无盘软件里自带的最新驱动版本手动更新:从网卡官网下载的最新驱动文件官方下载地址:https://www.realtek.com/zh-tw/component/zoo/category/network-interface-controllers-10-100-1000m-gigabit-ethernet-pci-express-software2.手动更新网吧驱动先解压压缩包 ,再把Install_Win10_10065_05032023.exe文件用winrar 解压出来 , 点PNP网卡那里的手动更新驱动 选择下面的路径如果非网维大师无盘可联系客服或技术员远程替换更新解决
-
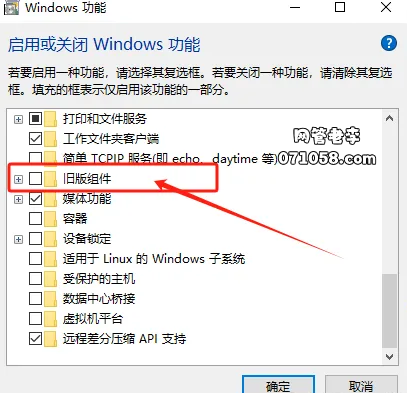
Win10/11玩帝国时代3游戏初始化失败解决方法 帝国时代3游戏启动后就提示初始化失败,不能正常进入玩耍!查阅相关资料后得知,当您玩20年代初的多人游戏时需要 "DirectPlay",DirectPlay 是 DirectX 的一部分,如果您想玩一款古老的多人游戏,需要在计算机上启用此功能;按照下面教程可在Windows11/10 电脑上启用 DirectPlay。方法如下:1、开始菜单上右键或在键盘上按下win+R 组合键打开【运行】2、在【运行】界面输入命令“control”并按回车键打开控制面板3、点击【程序】后进入,有个【启用或关闭 Windows 功能】4、点击【启用或关闭Windows功能】移动滑块找到【旧版组件】5、将下面的【DirectPlay】勾选,点击确定等待安装完成后即可
-
Debian 12 更换国内源 修改源文件路径:vim /etc/apt/sources.list阿里云源: deb https://mirrors.aliyun.com/debian/ bookworm main non-free non-free-firmware contrib deb-src https://mirrors.aliyun.com/debian/ bookworm main non-free non-free-firmware contrib deb https://mirrors.aliyun.com/debian-security/ bookworm-security main deb-src https://mirrors.aliyun.com/debian-security/ bookworm-security main deb https://mirrors.aliyun.com/debian/ bookworm-updates main non-free non-free-firmware contrib deb-src https://mirrors.aliyun.com/debian/ bookworm-updates main non-free non-free-firmware contrib deb https://mirrors.aliyun.com/debian/ bookworm-backports main non-free non-free-firmware contrib deb-src https://mirrors.aliyun.com/debian/ bookworm-backports main non-free non-free-firmware contrib清华大学源: deb https://mirrors.tsinghua.edu.cn/debian/ bookworm main non-free non-free-firmware contrib deb-src https://mirrors.tsinghua.edu.cn/debian/ bookworm main non-free non-free-firmware contrib deb https://mirrors.tsinghua.edu.cn/debian-security/ bookworm-security main deb-src https://mirrors.tsinghua.edu.cn/debian-security/ bookworm-security main deb https://mirrors.tsinghua.edu.cn/debian/ bookworm-updates main non-free non-free-firmware contrib deb-src https://mirrors.tsinghua.edu.cn/debian/ bookworm-updates main non-free non-free-firmware contrib deb https://mirrors.tsinghua.edu.cn/debian/ bookworm-backports main non-free non-free-firmware contrib deb-src https://mirrors.tsinghua.edu.cn/debian/ bookworm-backports main non-free non-free-firmware contrib中科大源: deb https://mirrors.ustc.edu.cn/debian/ bookworm main non-free non-free-firmware contrib deb-src https://mirrors.ustc.edu.cn/debian/ bookworm main non-free non-free-firmware contrib deb https://mirrors.ustc.edu.cn/debian-security/ bookworm-security main deb-src https://mirrors.ustc.edu.cn/debian-security/ bookworm-security main deb https://mirrors.ustc.edu.cn/debian/ bookworm-updates main non-free non-free-firmware contrib deb-src https://mirrors.ustc.edu.cn/debian/ bookworm-updates main non-free non-free-firmware contrib deb https://mirrors.ustc.edu.cn/debian/ bookworm-backports main non-free non-free-firmware contrib deb-src https://mirrors.ustc.edu.cn/debian/ bookworm-backports main non-free non-free-firmware contrib 网易源: deb https://mirrors.163.com/debian/ bookworm main non-free non-free-firmware contrib deb-src https://mirrors.163.com/debian/ bookworm main non-free non-free-firmware contrib deb https://mirrors.163.com/debian-security/ bookworm-security main deb-src https://mirrors.163.com/debian-security/ bookworm-security main deb https://mirrors.163.com/debian/ bookworm-updates main non-free non-free-firmware contrib deb-src https://mirrors.163.com/debian/ bookworm-updates main non-free non-free-firmware contrib deb https://mirrors.163.com/debian/ bookworm-backports main non-free non-free-firmware contrib deb-src https://mirrors.163.com/debian/ bookworm-backports main non-free non-free-firmware contrib腾讯云源: deb https://mirrors.cloud.tencent.com/debian/ bookworm main non-free non-free-firmware contrib deb-src https://mirrors.cloud.tencent.com/debian/ bookworm main non-free non-free-firmware contrib deb https://mirrors.cloud.tencent.com/debian-security/ bookworm-security main deb-src https://mirrors.cloud.tencent.com/debian-security/ bookworm-security main deb https://mirrors.cloud.tencent.com/debian/ bookworm-updates main non-free non-free-firmware contrib deb-src https://mirrors.cloud.tencent.com/debian/ bookworm-updates main non-free non-free-firmware contrib deb https://mirrors.cloud.tencent.com/debian/ bookworm-backports main non-free non-free-firmware contrib deb-src https://mirrors.cloud.tencent.com/debian/ bookworm-backports main non-free non-free-firmware contrib 更新源: sudo apt update
-
debian 12 设置静态ip和dns 1、设置静态ip查看网卡名称是ip address编辑网卡配置文件vi /etc/network/interfacesens33 是上步中查询到的网卡名称iface ens33 inet static 【static是改变网卡为静态模式】address 192.168.2.157 是ip地址netmask 255.255.255.0 是ip地址的子网掩码gateway 192.168.2.2 是ip地址的网关2、设置dnsdebian 12安装后默认没有/etc/resolv.conf 文件 建立此文件vi /etc/resolv.conf添加以下内容nameserver 114.114.114.114nameserver 8.8.8.8nameserver 8.8.8.4保存完毕后记得重启服务器
-
-
湖北电信/联通/移动DNS服务器地址大全 当网络设备连接到互联网时,计算机需要将域名转换为IP地址,以便正确路由请求到目标服务器。宽带运营商会提供主要的DNS服务器地址和备用的DNS服务器地址,以确保网络的稳定性和可靠性。以下是湖北电信DNS服务器、湖北联通DNS和湖北移动DNS服务器地址。以下DNS服务器适用湖北省以下城市:武汉市、黄石市、十堰市、宜昌市、襄阳市、鄂州市、荆门市、孝感市、荆州市、黄冈市、咸宁市、随州市、恩施土家族苗族自治州湖北电信DNS服务器:202.103.24.68202.103.0.68湖北联通DNS服务器:218.104.111.114218.104.111.122218.106.127.114218.106.127.122湖北移动DNS服务器:211.137.64.163211.137.58.20以上是湖北电信DNS、湖北联通DNS、湖北移动DNS服务器大全,DNS服务器的配置是确保你的设备能够正确地解析域名并与互联网上的各种服务进行通信的关键步骤。不同的的宽带运营商选择对应的DNS服务器,选择合适的DNS服务器可以提高性能、安全性和可靠性,从而改善你的互联网体验。
-
-
intel 以太网适配器驱动 29.4.1 文件介绍:此下载将安装面向支持的操作系统版本的 英特尔® 以太网适配器 Complete 驱动程序包 29.4.1 版。独立于操作系统, FreeBSD, Microsoft Windows, Linux, VMware大小:829.3 MBSHA256:1580A7E15E549651FEE0E7403BB8D1B05AFBCA911DC7B60CB9DDF73E5C058020此下载对下面列出的产品有效:英特尔® 以太网控制器 I226-LM英特尔® 以太网控制器 I226-IT英特尔® 以太网控制器 I226-VIntel® Ethernet Network Adapter I226-T1英特尔® 千兆 CT 台式机适配器英特尔® 82583V 千兆以太网控制器英特尔® 82580EB 千兆位以太网控制器英特尔® 82580DB 千兆以位太网控制器英特尔® 82579LM 千兆位以太网 PHY英特尔® 82579V 千兆位以太网 PHY英特尔® 以太网控制器 I210-AS英特尔® 以太网控制器 I210-IT英特尔® 以太网控制器 I210-CL英特尔® 以太网控制器 I210-AT英特尔® 以太网控制器 I210-IS英特尔® 以太网控制器 I210-CS英特尔® 以太网控制器 I211-AT英特尔® 以太网连接 I219-LM英特尔® 以太网连接 I219-V英特尔® 以太网连接 I218-V英特尔® 以太网连接 I218-LM英特尔® 以太网连接 I217-V英特尔® 以太网连接 I217-LM英特尔® 太网网络连接 I347-AT4适用于 OCP 3.0 的英特尔® 以太网适配器 I350-T4英特尔® 以太网服务器网卡 I350-T4V2英特尔® 以太网服务器网卡 I350-T2V2英特尔® 以太网服务器适配器 I350-F2英特尔® 以太网服务器适配器 I350-F4英特尔® 以太网服务器适配器 I210-T1英特尔® 以太网连接 X557-AT2英特尔® 以太网连接 X557-AT4英特尔® 以太网连接 X557-AT英特尔® 以太网控制器 X550-AT英特尔® 以太网控制器 X550-BT2英特尔® 以太网控制器 X550-AT2英特尔® 以太网控制器 X540-AT2英特尔® 以太网控制器 X540-BT2英特尔® 82599EN 万兆位以太网控制器英特尔® 82599ES 万兆位以太网控制器英特尔® 82599EB 万兆位以太网控制器英特尔® 以太网聚合网络适配器 X520-DA2英特尔® 以太网服务器网卡 X520-DA1,适用开放计算项目英特尔® 以太网聚合网络适配器 X520-T2英特尔® 以太网聚合网络适配器 X520-SR1英特尔® 以太网服务器网卡 X520-DA2,适用开放计算项目英特尔® 以太网服务器适配器 X520-DA2英特尔® 以太网融合网卡 X520-DA1英特尔® 以太网聚合网络适配器 X520-SR2英特尔® 以太网聚合网络适配器 X520-QDA1英特尔® 以太网聚合网络适配器 X520-LR1英特尔® 以太网融合网络适配器 X550-T1英特尔® 以太网融合网络适配器 X550-T2英特尔® 以太网控制器 XXV710-AM1英特尔® 以太网控制器 XXV710-AM2英特尔® 以太网控制器 XL710-BM1英特尔® 以太网控制器 XL710-BM2英特尔® 以太网控制器 XL710-AM1英特尔® 以太网控制器 XL710-AM2英特尔® 以太网控制器 V710-AT2英特尔® 以太网控制器 X710-TM4英特尔® 以太网控制器 X710-BM2英特尔® 以太网控制器 X710-AT2英特尔® 以太网控制器 X710-AM2英特尔® 以太网服务器适配器 XL710-QDA1,适用开放计算项目英特尔® 以太网服务器适配器 XL710-QDA2,适用开放计算项目英特尔® 以太网融合网络适配器 XL710-QDA2英特尔® 以太网融合网络适配器 XL710-QDA1Intel® Ethernet Network Adapter I710-T4L for OCP 3.0Intel® Ethernet Network Adapter I710-T4L适用于 OCP 3.0 的英特尔® 以太网适配器 E810-CQDA1英特尔® 以太网网络适配器 E810-CQDA2适用于 OCP 3.0 的英特尔® 以太网适配器 E810-CQDA2英特尔® 以太网网络适配器 E810-CQDA1英特尔® 以太网网络适配器 E810-2CQDA2适用于 OCP 3.0 的英特尔® 以太网适配器 E810-XXVDA4适用于 OCP 3.0 的英特尔® 以太网网络适配器 E810-XXVDA2英特尔® 以太网网络适配器 E810-XXVDA2英特尔® 以太网网络适配器 E810-XXVDA4英特尔® 以太网网络适配器 E810-CQDA2T适用于 OCP 的英特尔® 以太网网络适配器 E810-CQDA1英特尔® 以太网网络适配器 E810-XXVDA4T英特尔® 以太网控制器 E810-CAM2英特尔® 以太网控制器 E810-CAM1英特尔® 以太网控制器 E810-XXVAM2英特尔® 以太网网络适配器 I225-T1英特尔® 以太网聚合网络适配器 X540 T2英特尔® 以太网聚合网络适配器 X540 T1英特尔® 以太网控制器 I225-LM英特尔® 以太网网络适配器 XXV710-DA2 版英特尔® 以太网控制器 I350-AM2英特尔® 以太网控制器 I350-BT2英特尔® 以太网控制器 I350-AM4英特尔® 以太网融合网络适配器 X710-DA4英特尔® 以太网融合网络适配器 X710-T4英特尔® 以太网融合网络适配器 X710-DA2英特尔® 以太网网络适配器 XXV710-DA1 OCP 版英特尔® 以太网控制器 I225-IT英特尔® 以太网网络适配器 XXV710-DA1英特尔® 以太网网络适配器 XXV710-DA2英特尔® 以太网控制器 I225-V适用于 OCP 3.0 的英特尔® 以太网适配器 X710-DA2英特尔® 以太网网络适配器 X710-T2L适用于 OCP 3.0 的英特尔® Ethernet Network Adapter X710-T2L英特尔® 以太网网络适配器 X710-T4L英特尔® 82598EB 万兆位以太网控制器适用于 OCP 3.0 的英特尔® 以太网适配器 X710-DA4适用于 OCP 3.0 的英特尔® Ethernet Network Adapter X710-T4L英特尔® Ethernet Network Adapter XXV710-DA2T英特尔® 以太网服务器适配器 X710-DA2 for OCP英特尔® PRO 1000 PT 双端口服务器适配器英特尔® PRO 1000 PT 四端口窄板服务器适配器英特尔® PRO 1000 PT 四端口服务器适配器英特尔® PRO 1000 MF 服务器适配器英特尔® PRO 1000 MF 服务器适配器 (LX)英特尔® PRO 1000 MF 双端口服务器适配器英特尔® 82597EX 千兆位以太网控制器英特尔® 以太网连接 C827-AM1英特尔® 以太网连接 C827-IM1英特尔® 以太网网络连接 OCP X557-T2英特尔® 以太网连接 XL827-AM1官方下载页:https://www.intel.cn/content/www/cn/zh/download/15084/intel-ethernet-adapter-complete-driver-pack.html官方下载地址:https://downloadmirror.intel.com/842323/Release_29.4.1.zip网盘分流:https://url67.ctfile.com/d/8911067-156063982-671e54?p=3328 (访问密码: 3328)
-
磊科WiFi6电信版NX1-T升级固件 最近站长找到一款不错的WIFI可以AP模式 支持WIFI6买到手建议直接刷官方最新固件介绍:1800M家用WiFi6无线路由器支持WiFi6无线协议搭载1GHz高端芯片,256M闪存+128M内存全千兆端口享受千兆网速,1800Mbps无线双频信号MU-MIMO+OFDMA技术加持,延时更低,速度更快官方详解:产品型号 NX1-T (WiFi6)无线协议 IEEE802.11 b/g/n/ac/ax电信规范 符合电信e-OS标准端口 1个10/100/1000M自适应WAN口 3个10/100/1000M自适应LAN口转发速率 10/100/1000Mbps无线规格 2.4G频段:574Mbps;5G频段:1201Mbps天线 6根高增益全向天线CPU 1GHz双核RAM 256MB(内包在主IC中)ROM 128MB按钮 default×1LED指示灯 PWR、Internet、WIFI、LAN1、LAN2、LAN3、WANmesh按键 WPS×1外形尺寸 236mm×144mm×50mm电源 12V/1A(国标)产品图片:版本升级说明:更换全新界面,修复已知问题。网盘分享:https://url67.ctfile.com/d/8911067-155969009-9ce98c?p=3328 (访问密码: 3328)